MK Chou
FallFusion is a real-time, multimodal fall detection system that integrates both visual and audio streams. Leveraging a custom-trained CNN for action recognition and an LSTM for fall sound detection, the system employs Dempster-Shafer Theory (DST) for robust decision-level fusion. Optimized for the resource-constrained Jetson Nano 2GB, FallFusion features efficient memory management, seamless ONNX model deployment, and reliable GPIO hardware control, collectively enhancing system stability and practical deployment in real-world scenarios.
With an aging global population, falls have emerged as a leading cause of injury and mortality among the elderly. Conventional detection systems often depend on a single modality—such as cameras or microphones—which presents several limitations:
Therefore, we aim to design a system that can:
Conventional multimodal fusion techniques, such as direct score averaging, are often inflexible when dealing with uncertainty and conflicting evidence. For instance:
Directly combining scores in such cases may reduce system accuracy.
How DST addresses these issues:
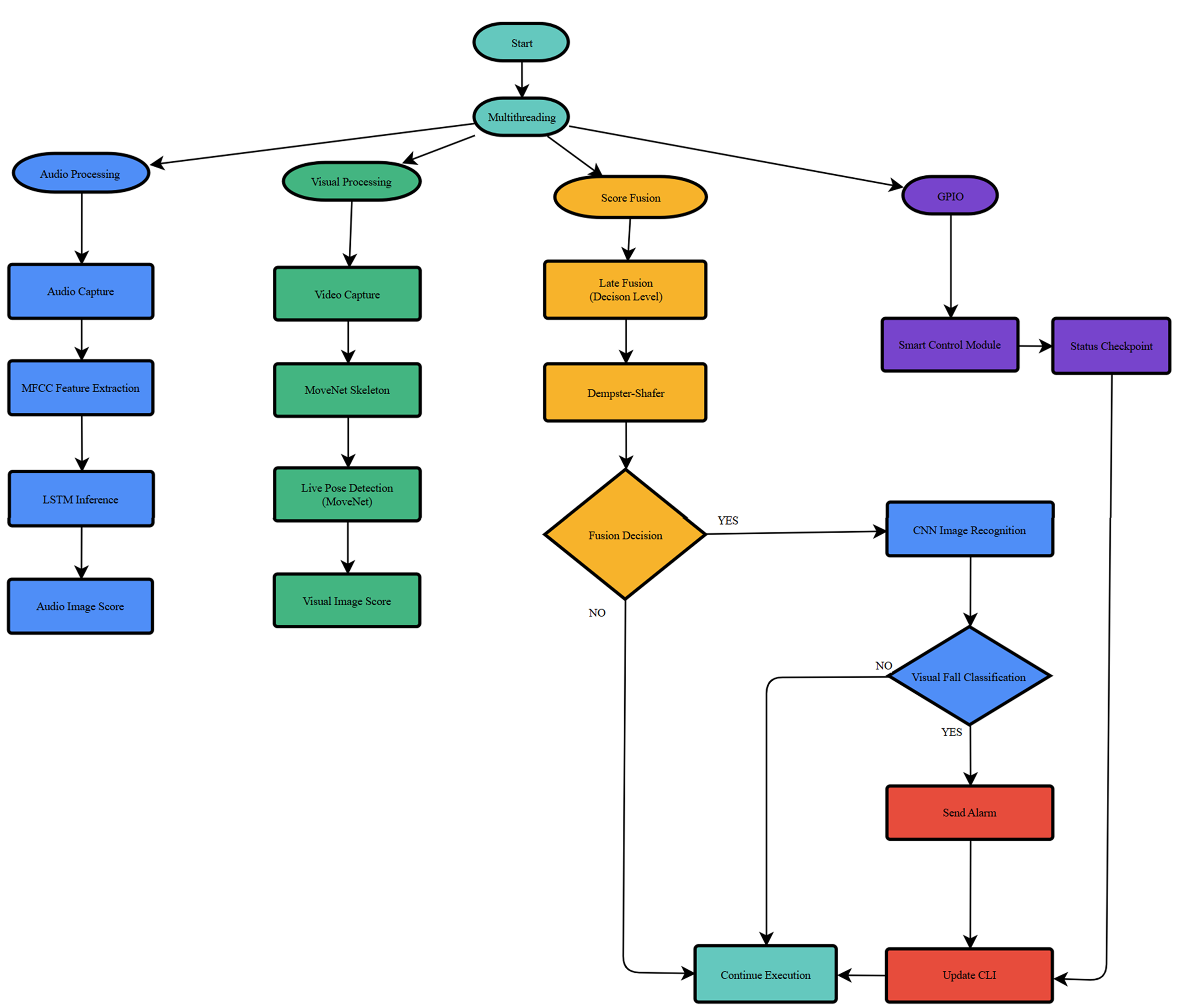
System architecture flowchart
The system synergistically integrates visual and audio modalities to achieve robust fall detection, even on low-resource embedded hardware. Its core components include:
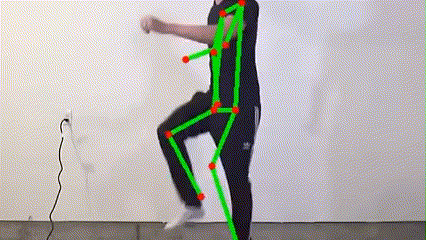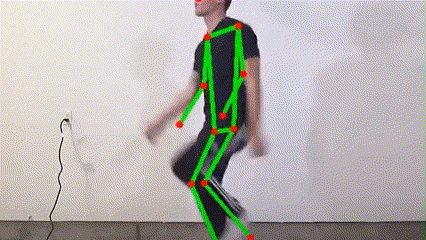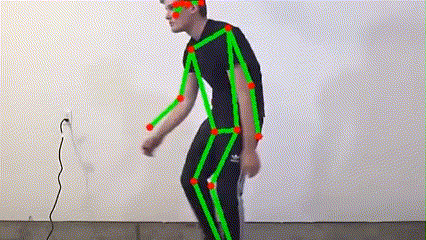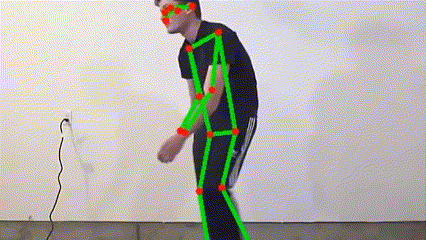
MoveNet, developed by Google, is a high-performance human pose estimation model renowned for its rapid inference and high accuracy. Its lightweight design is ideal for deployment on embedded devices such as Jetson Nano, enabling stable and accurate pose analysis even under resource constraints. With MoveNet, the system can instantly capture human motion changes, providing a solid foundation for subsequent fall detection and multimodal fusion.
MoveNet real-time keypoint detection demo

MoveNet applied to fall detection process animation
The system applies the MoveNet ONNX model for human pose estimation, detecting 17 keypoints (e.g., head, shoulders, elbows, knees) and outputting coordinates and confidence scores. These features are used to calculate body tilt angle and center of gravity, serving as the initial basis for fall detection. The process ensures high performance and low latency, suitable for embedded platforms.
To further optimize deployment, MoveNet is quantized to int8 and converted from tflite to onnx format. This significantly reduces model size and computational requirements with minimal impact on inference accuracy, enabling stable operation on resource-limited devices like Jetson Nano while maintaining real-time and precision.
When the DST fusion score surpasses a predefined threshold, a custom-trained CNN is activated for detailed action classification. This model, specifically tailored for the system, distinguishes among five human actions: standing, sitting, lying, bending, and crawling, each accompanied by a confidence score. If any action's confidence exceeds the alert threshold, the system promptly issues an alarm. This layered approach significantly reduces false positives and enhances the reliability of fall detection.
The training dataset used is from Fall Detection Dataset. Each folder contains sequential action images with a CSV file labeling the action type for each image. A total of 15,402 images were processed, split into 80% training and 20% validation sets. During training, both training and validation accuracy and loss are displayed in real time to monitor model learning and generalization.
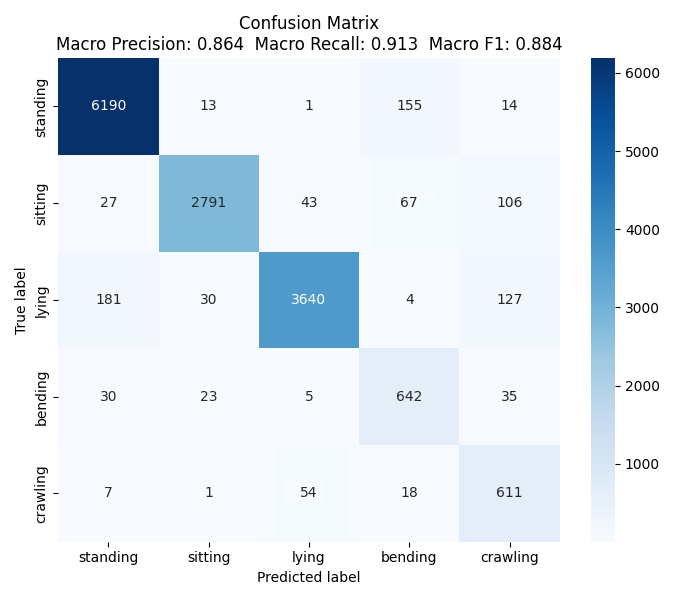
CNN action classification confusion matrix, showing prediction vs. actual distribution
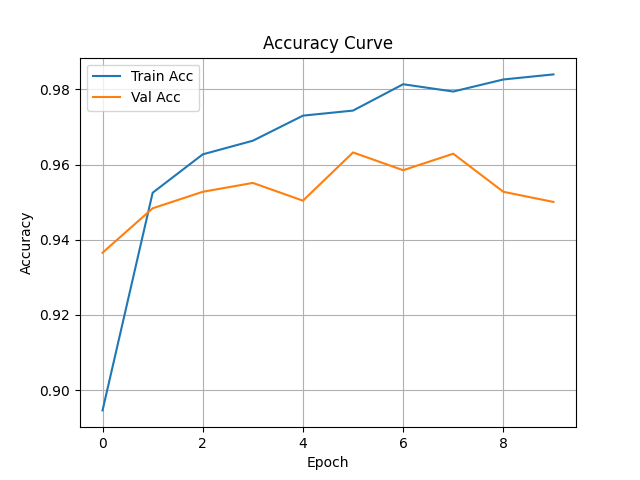
CNN training and validation accuracy curves
The audio module continuously acquires ambient sounds via a microphone, segmenting each recording into three-second samples. Post-processing steps—including noise reduction and volume normalization—are applied before converting the waveform into Mel Frequency Cepstral Coefficient (MFCC) features for model input.
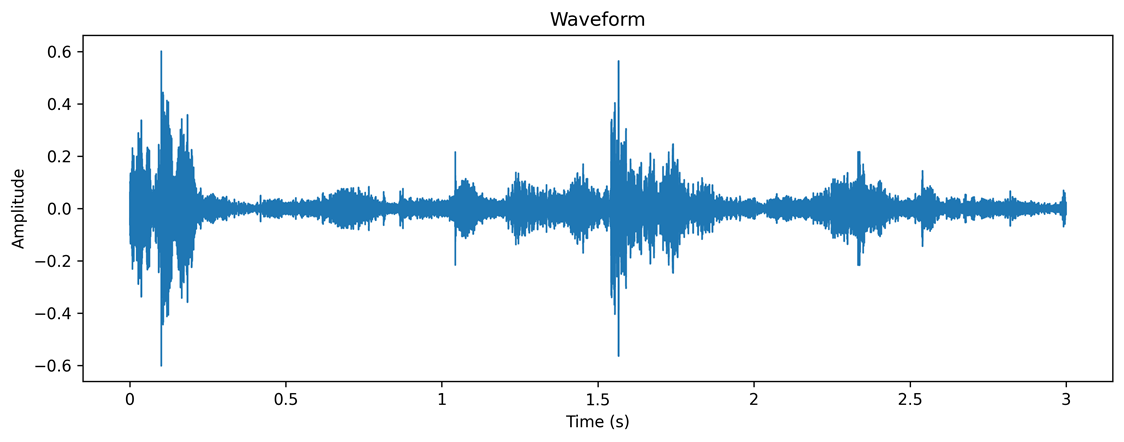
Original audio waveform
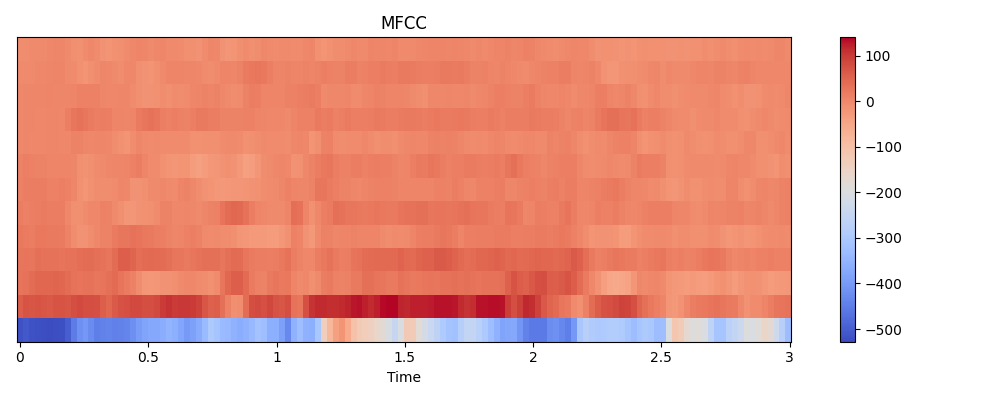
Audio waveform converted to MFCC feature for model input
The audio model is trained using the AFE: Sound Analysis for Fall Event detection dataset, which contains various fall events and daily environmental sounds, with each audio segment labeled as fall-related or not. These annotations help the model learn to distinguish fall sounds from general noise, improving recognition accuracy.
MFCC features are used as input to train the LSTM model for fall sound recognition. The following figures show the LSTM training loss/accuracy curves, test set confusion matrix, and ROC curve, demonstrating the model's excellent performance in classifying fall and non-fall events.
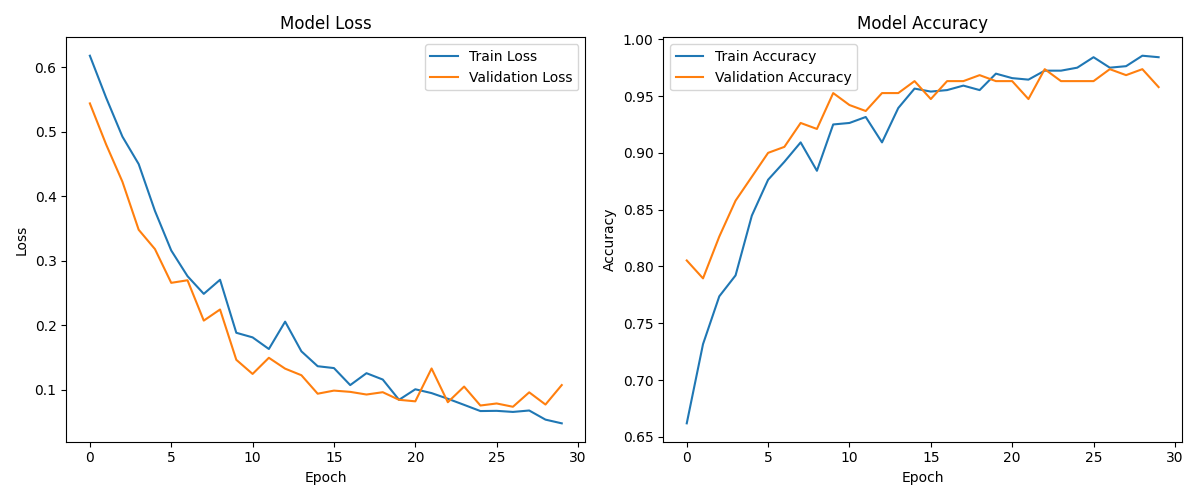
LSTM training loss and accuracy curves
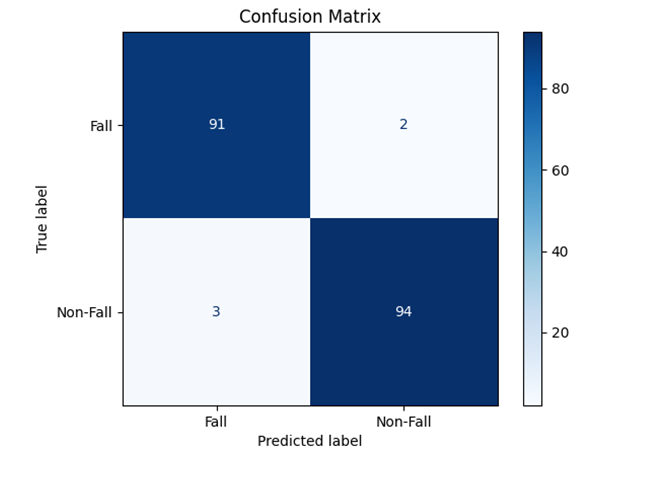
LSTM model confusion matrix on the test set
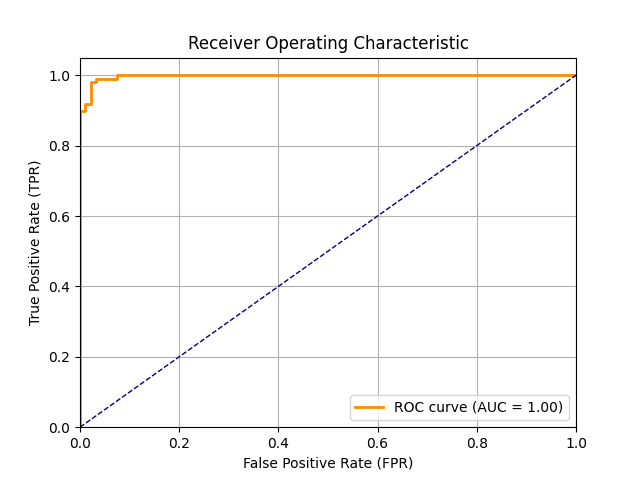
LSTM model ROC curve, AUC indicates excellent classification ability
At the heart of the system's multimodal decision-making lies Dempster-Shafer Theory (DST). Inference results from the visual (pose angles, CNN scores) and audio (LSTM scores) modules are first transformed into belief assignments. The DST fusion algorithm then calculates a unified confidence score and a conflict coefficient (K), quantifying the degree of disagreement between modalities.
Specifically, this system utilizes a late fusion (decision-level fusion) strategy. Instead of directly combining raw sensor data or features, each modality (vision and audio) independently produces its own decision or confidence score. These scores are then fused at the decision level using DST. This approach allows each model to fully leverage its strengths and makes the overall system more robust to noise or errors in any single modality. Late fusion is especially suitable for scenarios where sensor characteristics and data types differ significantly, as in this fall detection application.
The system is also designed to flexibly support different sensors and threshold settings for various environments. Depending on the deployment scenario, users can select the most appropriate combination of sensors (e.g., only vision, only audio, or both) and adjust the fusion or alert thresholds accordingly. This adaptability ensures optimal performance and reliability whether in a quiet home, a noisy public space, or other specialized settings.
When the DST fused confidence score exceeds a preset threshold, the system further activates the CNN model for multi-class action verification. If the CNN determines a high-risk action (such as lying or crawling) and the confidence exceeds the alert threshold, an alert signal (e.g., buzzer, LED) is triggered and the event is logged in the CLI Dashboard.
One major advantage of DST is its ability to dynamically handle conflicts between modalities. For example, when the visual and audio modules produce opposite results, DST calculates the conflict coefficient K and automatically adjusts the weights, assigning trust to the more reliable source. This prevents system failure due to misjudgment by a single modality.
DST-based fusion and decision-making significantly enhance the system's robustness and accuracy. Even when a single sensor is disturbed (e.g., poor lighting, environmental noise), the system can still make stable judgments based on multimodal information, reducing false alarms and missed detections. This makes it suitable for long-term automated monitoring applications.
The CLI Dashboard adopts a streamlined, text-based interface, presenting information in well-organized tables and blocks. Color coding (e.g., red for alerts, green for normal) facilitates rapid status recognition. Designed for clarity and efficiency, the interface is ideal for embedded devices and remote terminal access.
The CLI interface displays multiple key pieces of information in real time, including:
The lower part of the interface records all fall events with time, confidence score, and action type for easy query and tracking. When an alert is triggered, it is clearly marked, and users can confirm or reset events directly via the CLI.
The CLI Dashboard runs on various operating systems and supports remote SSH connections, making it ideal for embedded platforms (such as Jetson Nano) or server-side deployment. Its lightweight nature ensures smooth operation even in resource-constrained environments.
The CLI interface enables on-site personnel or remote maintenance engineers to instantly grasp system status, quickly respond to abnormal events, and serves as a foundation for long-term monitoring and data analysis. It is especially valuable in environments where graphical interfaces are unavailable (e.g., factories, edge devices).
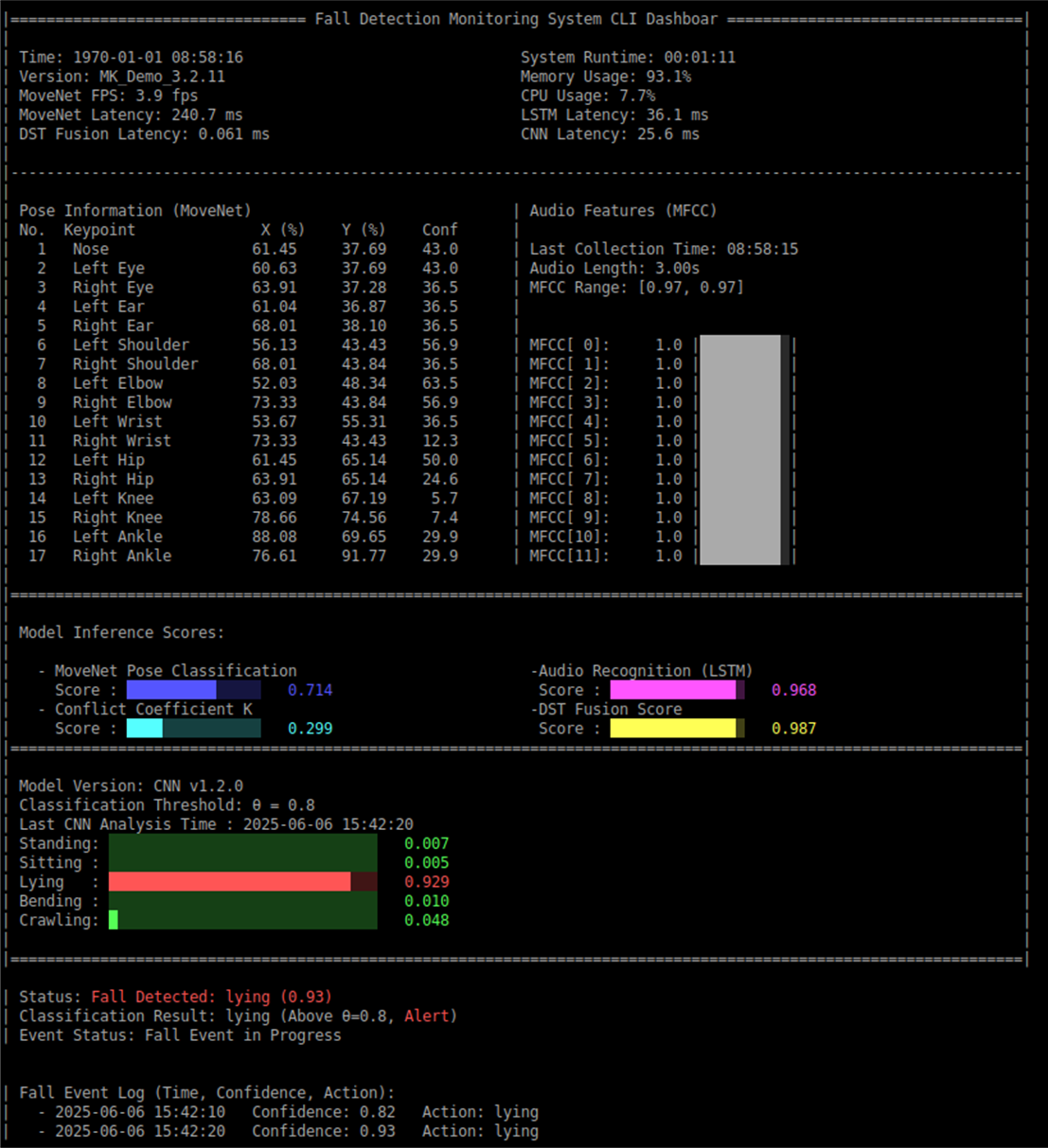
CLI Dashboard monitoring interface demo
The following table provides a comprehensive summary of the multimodal system, highlighting the integration of CNN and LSTM for action analysis and pose estimation, with DST fusion further enhancing overall performance.
| Model | Input Shape | Inference Latency | Accuracy | DST Fusion Latency | Status |
|---|---|---|---|---|---|
| CNN (5-class) | 192×192×4 | 20-40 ms | 87.4% | - | Deployed |
| LSTM (Audio) | 1×8×40 (MFCC) | 30-50 ms | 86.3% | - | Deployed |
| Pose Estimation | - | 250-350 ms | - | - | Deployed |
| DST Fusion | - | - | - | 50-60 us | Under evaluation |
This table demonstrates a multimodal system that combines CNN and LSTM for action analysis and pose estimation, leveraging DST fusion to further enhance overall performance. The system uses different input formats (image and audio features) and is designed for robust, real-time operation in diverse environments.


